The Harry Potter Fandom on AO3
The Archive of Our Own, or AO3, is, as the name says, an archive that hosts fan works of the most variable fandons on the internet. It is, currently, the most popular site to host fanfictions. So, as a person who loves fanfiction and data analysis, I decided to use my Python skills to learn a little more about the Harry Potter fandom on AO3. For that, I scraped relevant data (title, date of publication, kudos, hits, length, summary, comments and ships) of 500 works! Oof! To chose those 500 works that’d be analyzed, I sorted all the finished fics by most kudos, and then got to work.
Let’s see now how I did that! First, of course, importing the packages needed for all of this.
# Importing the packages
from bs4 import BeautifulSoup
from urllib.request import urlopen, Request
import requests
import pandas as pd
import re
import lxml
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
%matplotlib inline And then we’ll use BeautifulSoup to scrape all the data we want from the pages and store them neatly in a dictionary. But we all agree that going through all the pages necessary to compile 500 works is… a lot of work. But a little function can fix this easily, here it goes.
def getEverything(first, last):
# creating an empty dictionary to store the information i scrape
dic = {'Title': [], 'Date': [], 'Ship': [], 'Ship_category': [], 'Summary': [], 'Language': [], 'Word_Count': [], 'Comments': [], 'Chapters':[], 'Kudos':[], 'Bookmarks':[], 'Hits':[]}
while first != last:
# first while loop to scrape all the pages i want
url = f'https://archiveofourown.org/tags/Harry%20Potter%20-%20J*d*%20K*d*%20Rowling/works?commit=Sort+and+Filter&page={first}&work_search%5Bcomplete%5D=T&work_search%5Bcrossover%5D=&work_search%5Bdate_from%5D=&work_search%5Bdate_to%5D=&work_search%5Bexcluded_tag_names%5D=&work_search%5Blanguage_id%5D=&work_search%5Bother_tag_names%5D=&work_search%5Bquery%5D=&work_search%5Bsort_column%5D=kudos_count&work_search%5Bwords_from%5D=&work_search%5Bwords_to%5D='
response = requests.get(url)
html_page = BeautifulSoup(response.content, 'html.parser')
# scraping the page for all the articles, where the individual fics information are stored
article = html_page.find_all(role='article')
# second while loop to go through each one separetely
num = 0
while num != 20:
title = article[num].find(class_='heading').get_text(strip=True).split('by')[0] # separating the fic name from the author name and storing only the fic name
date = article[num].find(class_='datetime').get_text(strip=True)[-4:]
try: # checking if there is a relashionship tag, if not, passing
ship = article[num].find(class_='relationships').get_text(strip=True)
except AttributeError:
pass
ship_category = article[num].find(class_='category').get_text(strip=True).split(',')[0]
summary = article[num].find(class_='userstuff summary').get_text(strip=True)
language = article[num].find('dd',class_='language').get_text(strip=True)
words_count = article[num].find('dd', class_='words').get_text(strip=True)
comments = article[num].find('dd', class_='comments').get_text(strip=True)
chapters = article[num].find('dd', class_='chapters').get_text(strip=True)
kudos = article[num].find('dd', class_='kudos').get_text(strip=True)
bookmarks = article[num].find('dd', class_='bookmarks').get_text(strip=True)
hits = article[num].find('dd', class_='hits').get_text(strip=True)
num += 1
# appending the results in a dictionary
dic['Title'].append(title)
dic['Date'].append(date)
try: # printing N/A if there's no relationship tag
dic['Ship'].append(ship)
except:
dic['Ship'].append('N/A')
pass
dic['Ship_category'].append(ship_category)
dic['Summary'].append(summary)
dic['Language'].append(language)
dic['Word_Count'].append(words_count)
dic['Comments'].append(comments)
dic['Chapters'].append(chapters)
dic['Kudos'].append(kudos)
dic['Bookmarks'].append(bookmarks)
dic['Hits'].append(hits)
first = first + 1
return dicAnd after turning it into a dataframe, we get this pretty little thing here

Nice, right?
And now that we have this, we can do some analysis with the data. Like, for example, find out what’s the year distribution of those 500 fics.
years = fics['Date'].value_counts().to_frame().reset_index()
years.rename(columns={'index':'Year', 'Date':'Fics_Published'}, inplace=True)
years
plt.figure(figsize=(10,5))
plt.title('Number of Publications by Year', fontsize=20)
plt.ylabel('Number of Publications', fontsize=15)
plt.xlabel('Years', fontsize=15)
plt.bar(years['Year'], years['Fics_Published'], width = 0.5, color = 'red', edgecolor = "black")
plt.show()

Here we can see that most of this fics were published in recent-but-not-so-recent years. Recent enough to not be forgotten, but old enough to pass around so many people that it grabs thousands of Kudos.
And you can see that the most recent year here, closing the top 5, is 2020. The year the pandemic hit us all. Coincidence? I don’t think so. With people closed at home, I’m guessing time-consuming hobbies like writing and reading fanfiction found themselves with more space in people’s schedules.
Following, we’ll take a look at the gender pairing and most common ships.
Think we’ll find anything interesting?
ship_category = fics['Ship_category'].value_counts().to_frame().reset_index()
ship_category.rename(columns={'index':'Ship_category', 'Ship_category':'Apperances'}, inplace=True)
sc = ship_category[:5]
sc
plt.figure(figsize=(10,5))
plt.title('Most Popular Gender Pairing', fontsize=20)
plt.ylabel('Number of Apperance', fontsize=15)
plt.xlabel('Gender Pairing', fontsize=10)
plt.xticks(size = 10, rotation = 45)
plt.bar(sc['Ship_category'], sc['Apperances'], width = 0.5, color = 'red', edgecolor = "black")
plt.show()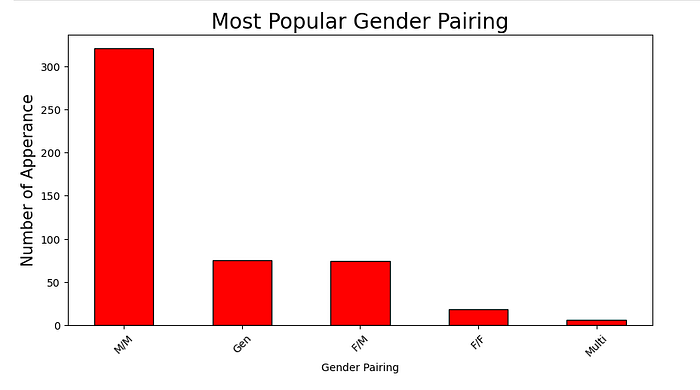
ships = fics['Ship'].value_counts().to_frame().reset_index()
ships.rename(columns={'index':'Ship', 'Ship':'Apperances'}, inplace=True)
ship = ships.head()
ship
plt.figure(figsize=(10,5))
plt.title('Most Popular Ships', fontsize=20)
plt.ylabel('Number of Apperance', fontsize=15)
plt.xlabel('Ship', fontsize=10)
plt.xticks(size = 10, rotation = 45)
plt.bar(ship['Ship'], ship['Apperances'], width = 0.5, color = 'red', edgecolor = "black")
plt.show()
As we know, the Harry Potter series have only one canonically gay character, and he was only confirmed gay after the book series was over.
Still, we can see that, wow, the vast majority of gender pairing in the fics are male/male, and the most popular couple is Harry Potter and his antagonist, Draco Malfoy.
So, a bit weird, no? If you, like me, read the books, you know there’s no queer bating in it. No obvious tension between those characters that the writers may be taking a step further. So why would this be the most popular pairing?
Believe it or not, but I have an explanation for you. Straight from my bachelor’s thesis. Looks like a literature major can be handy, no?
According to Sirpa Leppänen paper, Cibergirls in Trouble
[…] writers build up texts that explore gender and sexuality in ways that intervene into the discourse of the original cult texts in different ways. […] They use the discursive space of fan fiction to modify, question, parody, critique and radically subvert the ways gender and sexuality are represented in the cult texts.
So, no matter how much straight the writers make their characters be, one thing they need to be sure, is that fanfic writers will subvert it.
And this can be done with characters who are explored in the series, like Harry and Draco, who we know who they end up with, as well as less explored characters, like for example, Sirius Black and Remus Lupin.
Moving on, we’re checking the languages in which those works are written, think we’ll have any surprises?
language = fics['Language'].value_counts()
language
result:
English 500
Name: Language, dtype: int64Every single one of them was written in English. Which isn’t a surprise.
English being the international language, it seems that writing in it will give your work more exposure, even if it isn’t your first language. I, for example, am writing this article in English, although my first language is actually Portuguese.
Last, but not least, we’re creating a word cloud to check the most popular words used on the summaries.
summary_words = fics['Summary'].to_string()
stopwords = set(STOPWORDS)
for val in fics['Summary'].to_string():
val = str(val)
tokens = val.split()
for i in range(len(tokens)):
tokens[i] = tokens[i].lower()
summary_words += ' '.join(tokens) + ' '
wordcloud = WordCloud(width = 800, height = 800, background_color ='white', stopwords = stopwords, min_font_size = 10).generate(summary_words)
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0)
plt.show()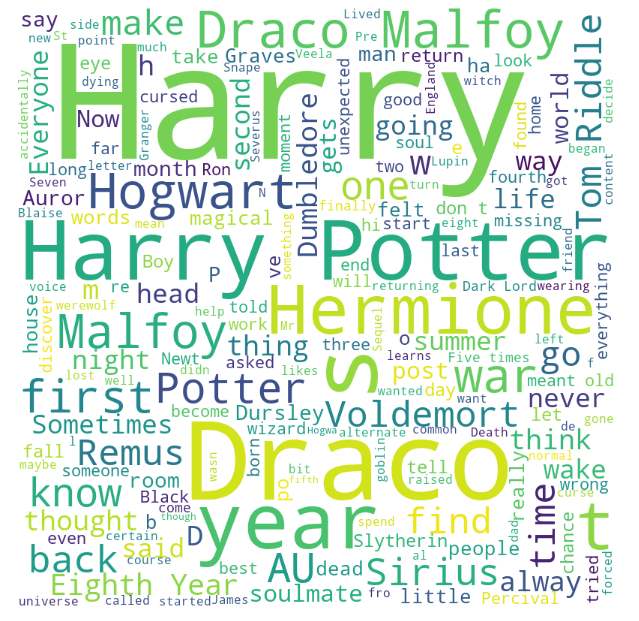
Not surprisingly, the name of the most popular couples are all there, as it seems to be very important to state the main couple presented in the work. Eighth Year and AU (alternative universe) also seem to be a reoccurring theme. This means that the authors are not only following the canon, but actively re-writing it, many times ignoring canon, and not only regarding the couples. Sometimes aspects of these re-writings get so famous among the fandom, they become almost canon, like the eighth year of schooling, for example. Canonically, Hogwarts offers 7 years of study, but among the fandom, it’s well accepted that after the war, the students went back to finish their education, creating the exceptional eighth year that’ve been incorporated by many writers.
As we reach the end of this article, I hope you learned a few things, not only about python and data scrapping, but also about Harry Potter, fanfics and how we use our creativity to explore ourselves!
